Semantic-Segmentation with the help of U-Nets
5 June 2019by Keyur Paralkar
Introduction / Summary:
This project focuses on building an UNET model for implementation of semantic segmentation on pascal voc 2012 dataset. Accuracy achieved 78.75% with output image size as 224x224.
Following are the tools and libraries used in this project:
Libraries used:
1) fast.ai 2) pytorch 3) matplotlib
Tools:
1) Jupyter notebook 2) PIL
There are some couple of questions first that we need to tackle: 1) What is meant by segmentation ? 2) What is semantic segmentation ? 3) Architecture used to achieve semantic segmentation ?
But before I answer these questions first we will take a look at our dataset that is being used in this task.
Dataset:
We are going to use pascal VOC dataset. This is one of the most famous academic purpose dataset and is highly used by research institues/labs or organizations to test their new algorithms on different task like object detection, segmentation etc. This dataset is divided into different years of challeges. For this project I have used The VOC2012 Challenge dataset.
Download the following:
1) Training/Validation data 2) Development kit code and documentation. 3) PDF documentation
From:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html#devkit
Alternative resource of downloading the dataset is using:
https://s3.amazonaws.com/fast-ai-imagelocal/pascal-voc.tgz
After downloading the development kit following will be it’s folder structure:
VOCdevkit/VOC2012
VOCdevkit/VOC2012/Annotations
VOCdevkit/VOC2012/ImageSets
VOCdevkit/VOC2012/JPEGImages
VOCdevkit/VOC2012/SegmentationClass
VOCdevkit/VOC2012/SegmentationObject
This dataset consists of images which belong to 20 different types of objects. Therefore, 21 classes for predictions including background(classs index=0):
Person: person
Animal: bird, cat, cow, dog, horse, sheep
Vehicle: aeroplane, bicycle, boat, bus, car, motorbike, train
Indoor: bottle, chair, dining table, potted plant, sofa, tv/monitor
Class indices for segmentation task:
0=background, 1=aeroplane, 2=bicycle, 3=bird, 4=boat, 5=bottle, 6=bus, 7=car , 8=cat, 9=chair, 10=cow, 11=diningtable, 12=dog, 13=horse, 14=motorbike, 15=person, 16=potted plant, 17=sheep, 18=sofa, 19=train, 20=tv/monitor
More example on segmentation on pascal voc dataset:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/segexamples/index.html
Now after getting basic understanding of structure of dataset we can revisit the questions we had, let’s move on to it.
Model
What is meant by segmentation ?
In simple terms segmentation is the task of segregating/dividing objects into specific categories. According to computer vision perspective, segmentation is pixel-wise classification i.e. each pixel in an image is categorized from the given set of classes. In our project there are total 21 classes (including background) so each pixel might belong to certain class. So our ultimate goal is to make pixel-wise prediction for a given input image. Images below can give a better understanding of how segmentation works:
 |
 |
 |
What is meant by semantic segmentation ?
There are two types of segmentation task:
Semantic segmentation which involes pixel-wise prediction for each unique object in an image. This task is class specific.
| Original Image | Semantic segmentation map |
|---|---|
 |
 |
Instance segmentation is a task which involes pixel-wise prediction for each object in an image with different color coding. This task is object specific. We can consider instance segmentation as a type of object detection problem but instead of bounding box we have mask on the detected objects.
| Original Image | Instance segmentation map |
|---|---|
 |
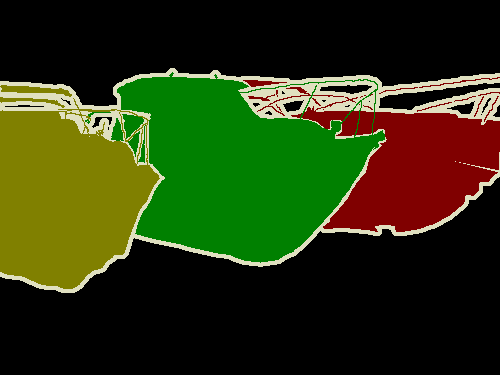 |
Architecture used to achieve semantic segmentation ?
For implementing semantic segmentation different neural network models can be used. For this project I am using UNETs which involves series of convolution followed by upsampling or transposed convolution with skip connection to corresponding convolution layers.
Unets
UNETs are convolutional neural network architecture which involves convolution of input image on one end so as to extract features, to transposed convolution which involves upscaling or enlargement of the features that are extracted such that output image’s size is equivalent to input image’s size. But there is one catch over here, if we apply transposed convolution to features that have extracted then this will generate a coarse output i.e. not refined output. To generate a fine grained output segmentation map we need to add skip connection which is nothing but addition of respective convolution layer’s output to transposed convolution and passing this combined output as input to the next transposed convolution operation.
According to the paper U-Net: Convolutional Networks for Biomedical Image Segmentation U-Net architecture is described is as follows:
The architecture consists of a contracting path to capture context and a symmetric expanding path that enables precise localization.
Here contracting path is also called as downsampling path (feature extraction by CNN) and symmetric expanding path is called as upsampling by transposed convolution(Symmetric by addition of skip connection) which would give precise location of extracted features.
Image below will give more clear understanding of the structure of U-Nets:
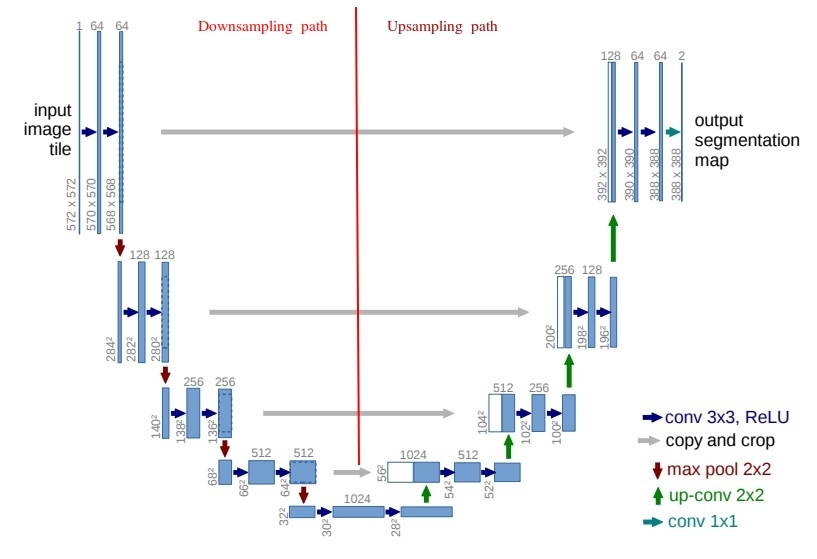
Implementing in code:
I have implemented the code for this model in python3.6 using fast.ai library which is based on pytorch. You can find implementation of this project in the repo. Let’s now proceed towards implementing the code for our unet model in jupyter notebook.
NOTE: This section focuses on challenges that I faced while implmentating the project. For better understanding of fastai library please go through the following documentation. Since this project is built in jupyter notebook therefore I have added some notes to each cell that might help you guys to understand the code better.
First we should import all the necessary libraries and packages needed for implementation.
import fastai
from fastai import *
from fastai.vision import *
import pathlib
import os
from PIL import Image
import matplotlib.pyplot as plt
fastai.vision is a module in fastai which consists of all the necessary tools for data preparation and training computer vision models. For better understanding of fast.ai library I would suggest read their documentation:
https://docs.fast.ai/
In fastai, entire train, valid and test data can be packed/binded inside a object called as Databunch. Databunches can be created using predefined classes or by using datablocks api. In this jupyter notebook we are going to use datablock api for creating our dataset. Datablock API let us customize the creation of Databunch by isolating the underlying parts of that process in separate blocks which mainly includes inputs and how to create them, splitting the data, labels to the input, transformation to apply, addition of test set and finally wraping the dataloader and creaeting databunch.
For our creation of dataset we are going to use SegmentationItemList class provided by fastai and we will also add some minor tweaks to this function so that we can load our data properly.
SegmentationItemList:
SegmentationItemList like ImageList but will default labels to SegmentationLabelList. ImageList is collection of items with len and getitem with ndarray indexing semantics for computer vision datasets. In short, SegmentationItemList and SegmentationLabelList are both ItemList suitable for segmentation task and masks.
Since I was working on older versions of fast.ai library therefore these changes are already incorporated into the library in the recent versions. For Segmentation task in PASCAL VOC dataset we are provided with ground-truth images in PNG format. This ground-truth image should have pixel values between 0-21(?). This can be achieved by opening these image in P mode. We need to pass this mode value into open_mask(). This is again a wrapper to PIL’s Image.open() function.
def open(self, fn): return open_mask(fn,convert_mode='P') #HERE
This function needs to be overriden in SegmentationItemList class:
class SegmentationLabelList(ImageItemList):
"`ItemList` for segmentation masks."
_processor=SegmentationProcessor
def __init__(self, items:Iterator, classes:Collection=None, **kwargs):
super().__init__(items, **kwargs)
self.classes,self.loss_func = classes,CrossEntropyFlat(axis=1)
def new(self, items, classes=None, **kwargs):
return self.new(items, ifnone(classes, self.classes), **kwargs)
def open(self, fn): return open_mask(fn,convert_mode='P') #HERE
def analyze_pred(self, pred, thresh:float=0.5): return pred.argmax(dim=0)[None]
def reconstruct(self, t:Tensor): return ImageSegment(t)
One important aspect of creating model was creation of LOSS function. We are going to use nn.CrossEntropyLoss() present in pytorch. Since we opened our image in P mode therefore some pixel values are going to be 255. As Pallete mode opens the images in between the range of 0-255. Therefore we need to ignore 255 pixel values from our images. This can be done by passing attribute ignore_index=255 to nn.CrossEntropyLoss() . This attribute will ignore the pixels which has intensity value equal to 255. We are Ignoring this 255 value because this value is not we are working i.e. we are only focusing on values in range of 0-21.